网安智库|我国人工智能安全检测能力现状及治理建议
摘 要:人工智能大模型现象级的火爆,促使人工智能与实体经济的加速融合与应用。人工智能安全治理攸关全人类命运,通过测试评估防范安全风险,推进人工智能发展与提升人工智能安全治理能力已成为全人类的共识。针对人工智能安全威胁由局部攻击向系统化协同攻击演化,导致单一的检测与防护技术无法应对复合攻击的问题,因此加速提升人工智能安全检测能力,保障人工智能安全刻不容缓。通过梳理人工智能安全检测政策背景、安全风险、能力现状,提出了治理建议,对人工智能产业安全发展具有重要意义。
内容目录:
1 政策背景
2 安全风险
3 能力现状
4 治理建议
5 结 语
人工智能(Artificial Intelligence,AI)是推动经济社会向智能化跃进的重要引擎,在给世界带来巨大机遇的同时,也带来难以预知的各种风险和复杂挑战。AI 安全治理攸关全人类命运,通过测试评估防范安全风险,推进 AI 发展与提升 AI 安全治理能力已成为全人类的共识。AI 安全治理旨在解决安全风险和科技伦理问题。AI 在其自身发展带来新的网络空间伴生安全威胁的同时,也给传统的网络空间安全从攻击和防护 2 个方面带来了巨大的赋能安全效应。本文 AI 安全检测能力特指针对 AI 伴生安全的检测能力。
为了保障 AI 技术和 AI 应用的安全性、可靠性和可控性,国家科技部、工信部高度重视AI 安全检测能力,以专项项目和“揭榜挂帅”评比等方式,鼓励企业、高校和科研院所等单位研发 AI 安全检测技术,保障 AI 研发、上线和运营全生命周期的安全性。通过分析现阶段国内外 AI 安全检测政策背景、AI 安全风险和我国 AI 安全检测能力的现状,给出 AI 安全治理建议,以期提升 AI 与实体经济融合发展和安全应用能力。
1政策背景
世界各国面临的共同课题是 AI 安全治理关乎整个人类的命运。2023 年,全球多个国家和组织纷纷出台倡议或规范,一致要求通过安全测试和评估等措施,确保 AI 安全可信。
2023 年 11 月 1 日,首届全球 AI 安全峰会上,28 国联署发布全球第一份针对 AI 的国际性声明《布莱切利宣言》,该声明表明需在 AI整个生命周期中考虑安全问题,开发者对高风险的 AI 系统安全性负有重大责任,需要采取适当的措施,如安全测试和评估等,以衡量、监测和缓解 AI 潜在的有害能力及其可能带来的影响。
2023 年 10 月 30 日,七国集团发布《开发先进人工智能系统组织的国际行为准则》,共包含 11 项内容,强调了开发过程中应采取的措施,以确保人工智能系统的可信性、安全性和保障性。其中,开发人员需要通过红队测试、测试和缓解措施等方式识别并减轻风险。同时,开发者也需要对部署后的漏洞、事件、业务模式进行识别和风险分析,包括监控漏洞和事件,推动第三方和用户发现并上报问题。
2023 年 10 月 18 日,中央网信办发布《全球人工智能治理倡议》,推动建立风险等级测试评估体系,实施敏捷治理,分类分级管理,快速有效响应。研发主体需要提高 AI 可解释性和可预测性,以提升数据真实性和准确性,确保AI 始终处于人类控制之下,打造可审核、可监督、可追溯和可信赖的 AI 技术。同时,积极开发相关技术及应用,用于 AI 治理,支持应用 AI技术进行风险防范和治理能力提升。
2安全风险
受益于近年来深度学习技术的不断发展,“AI+”赋能千行百业,其安全风险也逐步显现。在金融行业,“刷脸登录”“刷脸支付”等技术使人类生活更加便利,但是容易受到针对使用场景及算法模型的逃逸攻击、假冒攻击的威胁,造成经济损失;在政务领域,依托于 AI 可以实现业务的智能合约,重构并实现跨层级、跨地域、跨系统、跨部门、跨业务的信任和协同,但针对核心数据可能引发不可逆转的泄密事件;在电子商务行业,智能客服、智能推荐系统等大幅提升了电子商务管理平台的工作效率,但通过数据投毒等攻击手段可能使系统功能失效造成不必要的经济损失。
AI 安全框架如图 1 所示 ,包含安全目标、安全风险、安全测评、安全保障 4 大维度。AI安全实践分为 4 个核心步骤:第 1 步设立人视角的应用安全和系统视角的技术安全目标,第 2步梳理 AI 衍生和内生安全风险,第 3 步测评数据、算法、基础设施和系统应用风险程度,第 4步运用管理和技术相结合的方式保障安全。内生安全是 AI 技术自身在鲁棒性、可解释性等方面存在的缺陷;衍生安全是 AI 技术在应用的过程中,由于不当使用或外部攻击造成 AI 系统功能失效 。总体而言,AI 安全风险主要包含以下 4 类。
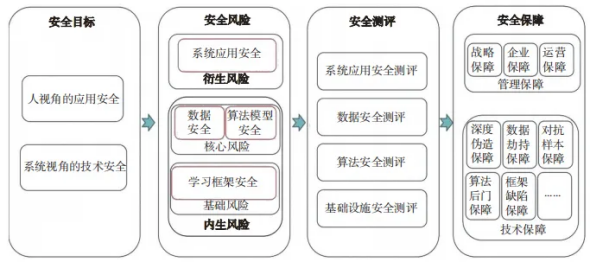
图 1 AI 安全框架
(1)数据安全风险。攻击者利用模型的输出信息类型可以开展模型盗取攻击和训练数据盗取攻击,在机器学习模型训练和应用过程中,所使用的数据和模型参数都有被泄露的风险。攻击者根据目标攻击模型查询样本获取目标攻击模型的预测结果,从而导致模型参数泄露,生成替代模型进而构成知识产权的侵犯。攻击者也可以推断训练数据集是否隶属于目标攻击模型,进而获得相关信息及训练数据的隐私信息,再使用特定的测试数据进行攻击。
(2)算法模型安全风险。针对深度学习算法提取样本特征的特点,在不改变目标深度学习系统的前提下,通过构造输入样本,使系统输出错误的结果以对抗样本攻击,可分为假冒攻击(即定向攻击)和躲避攻击(即非定向攻击)。攻击者误导深度学习系统输出特定的错误结果,例如攻击者 A 可以解锁用户 B 手机中的人脸识别系统。攻击者也可以误导深度学习系统输出非特定的错误结果,例如攻击者在监控摄像头下实现人员隐身或身份误判。
(3)学习框架安全风险。AI 算法基于学习框架完成模型搭建、训练和运行,深度学习框架需要依赖于大量的基础库和第三方组件支持,组件的依赖复杂度会严重降低深度学习框架的安全性 。某个组件开发者的疏忽,或者不同组件开发者之间开发规范的不统一,都可能向深度学习框架引入漏洞。攻击者可以基于控制流改写 AI 系统的关键数据,或者通过数据流劫持控制代码执行,实现对 AI 系统的干扰、控制甚至破坏。
(4)系统应用安全风险。不当使用(滥用、误用)、外部攻击(注入攻击)和业务设计安全(权限设置、功能安全)都会引发 AI 系统应用安全风险。攻击者通过提示词技术输入错误数据使AI 系统自学习到错误信息,也可以通过智能终端、应用软件的漏洞对 AI 系统实施注入攻击,如以人脸识别系统、智能语音助手为入口攻击后台业务系统,还可以利用业务设计缺陷实施攻击,如角色操作权限设置不当、应用场景风险考虑不足。
3能力现状
目前,我国在 AI 安全领域已取得一定成果,但安全检测、防护和监测预警技术仍不够完善,导致 AI 在高安全等级领域应用落地受到制约。AI 安全治理是一个复杂庞大的系统性工程,需从 AI 安全理论、标准和检测 3 个方面,全面夯实 AI 安全体系。
学术界形成了 AI 鲁棒性、公平性、可解释性和隐私性等理论研究 。
在鲁棒性方面,通过模型表现、样本扰动和模型边界综合评价模型的鲁棒性,模型表现是指模型在不同对抗环境下的性能,样本扰动是指评估对抗样本与自然样本的平均结构失真度,模型边界是指在模型预测正确前提下的样本扰动程度。
在公平性方面,从数据群体和数据个体的角度评估数据集,训练并计算数据集的潜在歧视程度。
在可解释性方面,通过解释保真度、解释可信度和平均定位准确率等方法给出样本可解释性等级。
在隐私性方面,隐私性评估指标代表数据泄露行为的风险等级,分为低风险、中风险与高风险。
国标委制定了 AI 算法安全、数据安全和生成式 AI 服务安全等方面的标准规范。
在算法安全方面,国家标准 GB/T 42888—2023《信息安全技术 机器学习算法安全评估规范》规定了机器学习算法技术和服务的安全要求与评估方法,以及机器学习算法安全评估流程,指导相关方保障机器学习算法生存周期安全及开展机器学习算法安全评估。团体标准 AIOSS-01-2018《人工智能深度学习算法评估规范》提出了 AI 深度学习算法的评估指标体系,制定了评估流程,以指导相关方对深度学习算法的可靠性开展评估工作。
在数据安全方面,GB/T 37988—2019《信息安全技术 数据安全能力成熟度模型》评估机构数据安全能力,用组织的能力成熟度来评估安全风险,从技术维度对数据生存周期安全过程进行测评。特别在生物特征识别领域有GB/T 41819—2022《信息安全技术 人脸识别数据安全要求》、GB/T 41773—2022《信息安全技术 步态识别数据安全要求》、GB/T 41807—2022《信息安全技术 声纹识别数据安全要求》、GB/T 41806—2022《信息安全技术 基因识别数据安全要求》4 项数据安全标准,规定了对人脸识别、步态识别、声纹识别、基因识别的数据收集、存储、传输、使用、加工、提供、公开、删除等数据处理活动的安全要求。
在生成式 AI服务安全方面,在研国家标准《网络安全技术生成式人工智能服务安全基本要求》《网络安全技术 生成式人工智能数据标注安全规范》《网络安全技术 生成式人工智能预训练和优化训练数据安全规范》,规定了生成式 AI 服务在语料安全、模型安全和安全措施等方面的基本要求,及预训练数据、优化训练数据和数据标注安全的要求及测评方法。
产业界研发了 AI 安全检测、防护和监测预警技术、工具和平台。
在技术方面,重点研发模型数据泄露测评技术、数字世界和物理世界对抗攻击测评和防护技术、模型后门检测和防护技术、多场景模型安全测评技术、模型供应链监测预警技术等。
在工具方面,主要包括针对机器学习框架的安全性评测工具360 AIFater、对抗环境下的算法安全性检测与加固的工具华为 MindArmour、百度 AdvBox。
在平台方面,主要有通用 AI 安全检测平台、AI 算法安全检测平台、大模型安全检测平台、生态链安全检测平台和 AI 安全风险监测预警平台。
其中,通用 AI安全检测平台覆盖数据、算法 / 模型、框架和系统多个维度,可全面评估 AI 系统安全状况,如浙江大学“AI 安全评测平台 AIcert”;AI 算法安全检测平台支持针对对抗样本攻击、模型后门攻击等安全风险的检测和防御,如瑞莱智慧“AI安全平台 realsafe”;大模型安全检测平台针对大模型的幻觉、偏见歧视、数据隐私等安全风险,以及生成式内容滥用于恶意活动的危害,提供全面系统的自动化检测和防御,如蚂蚁科技“蚁天鉴大模型安全检测平台”;生态链安全检测平台覆盖数据处理、训练,模型转化、部署,服务上线、运营,检测范围包含大模型应用服务、机器学习运维平台、云端机器学习训练等 AI 软件生态链安全检测,如奇虎科技“AI 系统安全检测平台 AISE”;AI 安全风险监测预警平台面向制造、金融、政务、电商和交通等行业,覆盖图像识别、人脸识别、目标检测和生成式 AI等关键应用场景,通过捕获智能系统在行业应用的安全等级和需求,实时监测业务场景并提供风险预警,如电子科技大学“AI 风险监测预警平台”。
4治理建议
我国 AI 发展正进入技术创新迭代持续加速和融合应用拓展深化的新阶段,亟须进一步完善AI 发展应用的治理方案、标准体系和检测能力,为 AI 促进经济高质量发展提供有效安全保障。
一是研究 AI 安全可信指南,制订适宜国情的治理方案。在全球化的背景与浪潮下,积极参与国际 AI 治理相关工作,提升我国国际规则制定的参与度和影响力。结合我国 AI 产业的发展特点,借鉴国外 AI 安全风险治理原则、政策和标准等,明晰各方责任、管理技术结合、贯穿生命周期和动态平衡调整的要求,从内设架构、制度建设、目标设计、数据管理、模型训练、测试验证、运营监测和协同沟通 8 个维度开展AI 设计、开发、部署、使用和维护全生命周期的安全治理。
二是统筹规划 AI 安全标准体系,加强基础安全、应用安全方面的标准制定。鼓励产学研用各方积极参与国际标准化工作,加快制定国家标准、行业标准和团体标准。研制 AI 通用安全参考架构,保障 AI 系统安全所涉及的利益相关方、相关方角色活动和安全功能视图等,为后续具体规范 AI 各方面安全提供参考。研制 AI开源框架、AI 开发平台、AI 计算平台方面的安全标准,为 AI 核心资产提供安全的运算环境以及具有针对性的安全保护措施。除此之外,还需深化 AI 应用安全标准的研究,如大语言模型应用安全技术规范。
三是加快建设 AI 安全检测能力,不断提升AI 技术的安全性、可靠性、可控性和公平性。以数据、模型为两大核心要素,实现 AI 系统在数据采集、模型训练、模型推理及模型部署等全生命周期的安全性检测、量化评估与防御加固,提升 AI 系统安全性与鲁棒性,同时对人脸识别身份认证和自动驾驶智能感知等应用场景下的模型提供防御加固能力。大模型的发展将会产生一些新的安全攻击手段与漏洞,应前置考虑大模型合规、幻觉、偏见歧视和数据隐私等问题,防御思路从被动变为主动。
5结 语
AI 大模型风靡全球,从感知到认知,从专用到通用,从判别式到生成式,从单模态到多模态交互,创造了通用 AI 到来的可能,AI 正在全球范围内迎来新一轮高速发展。我国发布《全球人工智能治理倡议》等文件,强调建立风险等级测试评估体系,利用 AI 技术防范风险,提升治理能力。
此外,我国 AI 治理方案、标准体系和检测能力都已经初步建立,下一步还需与应用场景相结合深化现有治理能力,实现 AI 促进经济高质量发展和高水平安全的统一。受限于作者的认知水平,本文分析的 AI 安全检测能力现状的维度不够全面,研究的技术深度不足。下一步,将与实际案例结合,深入研究如何通过 AI 安全检测护航 AI 安全。
文章选自《信息安全与通信保密》2024年第5期
上一篇:多名年轻干部泄密被查!
 等保测评咨询
等保测评咨询
